
When designing computational systems at Oblong, we consider all the technologies and people that inhabit a space. In a typical workspace or conference room, there may be several shared displays, laptops, mobile devices, cameras, input devices, servers, and, of course, people. Our spatial operating environment, g-speak™, makes it possible to construct meaningful relationships between the devices, displays, and people that share a physical space.
The One True Coordinate System
Most operating systems describe a display's pixel space using a 2-dimensional coordinate system with the origin (0,0) in the top left-hand corner of the screen. What does it mean to add a second display under these conditions? And what if that second display is at a ninety-degree angle to the first? Describing both displays in 2-dimensional space is no longer possible.
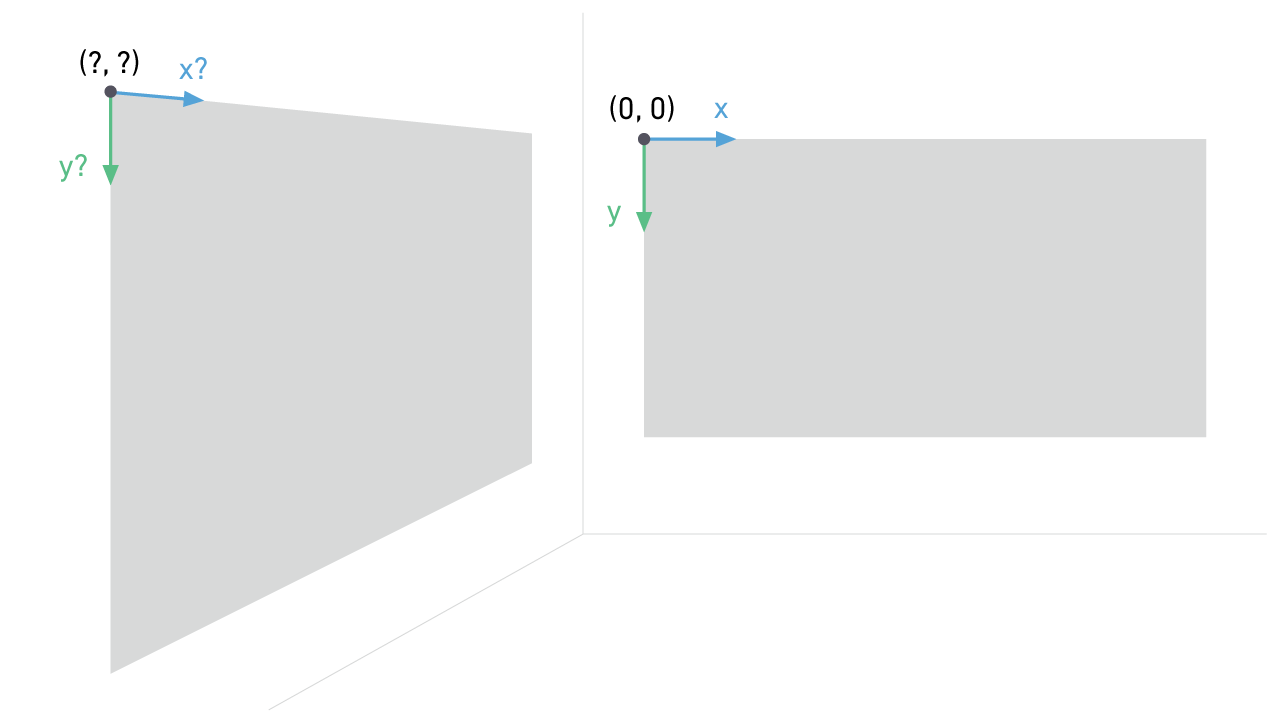
Oblong's g-speak uses a 3-dimensional coordinate system to describe displays and address pixels. We pick a central point, usually on the floor in the middle of the room, as the origin—our (0, 0, 0). From that origin, we can describe the location (and orientation) of any screen in space and create useful relationships between the different displays. This single, universal coordinate system also describes points beyond the boundaries of the screens, such as walls or surfaces, where no pixels are present at all.
Tracking Quality for Interaction Quality
The input devices that we design and build at Oblong are tracked and described—like the displays they interact with—in 3-dimensional space. Where other computing systems might know only the relative location of devices on a network, g-speak expresses the absolute position and orientation (the "pose") of an input device. This implies that you also know the attitude of each input device relative to a screen, or screens, because they live in the same conformed space. This is a qualitatively richer representation than the generic proximity descriptions of most consumer electronic devices. By virtue of this approach, pixel-less regions, as well as physical objects within the room, are also addressable by the interface and thus can become an integral part of the experience.
Space as Input
Because our input devices and displays occupy a single 3D coordinate system, it's possible to create natural interactions such as touch, hover, and free space gestures. Touch describes a physical connection with a screen. Hover describes an interaction near a screen, in which visual feedback depicts proximity to interface elements. And with an input device (a hand, a spatial wand) in free space, more expressive interactions become possible, including interactions that rely on or express spatial connection between user intent and the objects in a room. Chief among these, of course, is pointing.
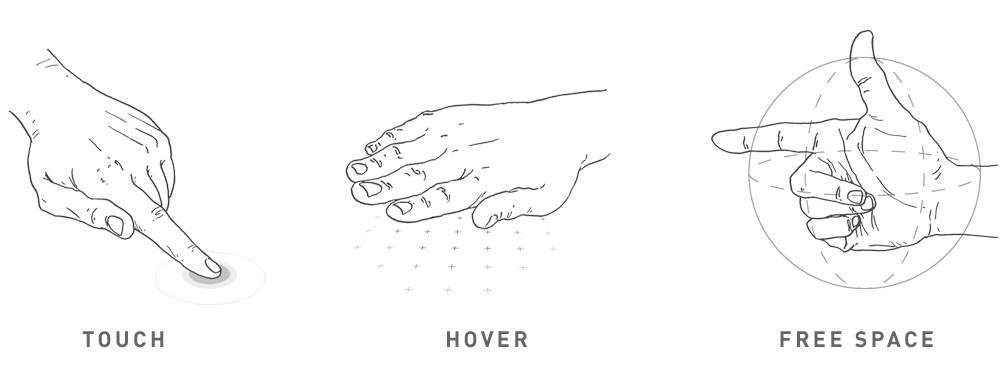
Utilizing all three, the vocabulary for designing intuitive, spatial interactions is greatly expanded. No other system simultaneously enables pointing at a whiteboard and clicking to capture its current state; dragging content from one wall to another; proximally transferring information from a personal device to large shared display; or dropping a digital asset onto a physical device to print it.
Cognitive Geometries
As it happens, pointing is a central and crucial gesture. When a person points an input device or hand to interact with
displays, other participants understand the area of focus through their inherent ability to know where the person is pointing. The gesture is thus simultaneously meaningful to the performer, to the observer, and to the digital system. Such shared geometric understanding is immensely powerful.
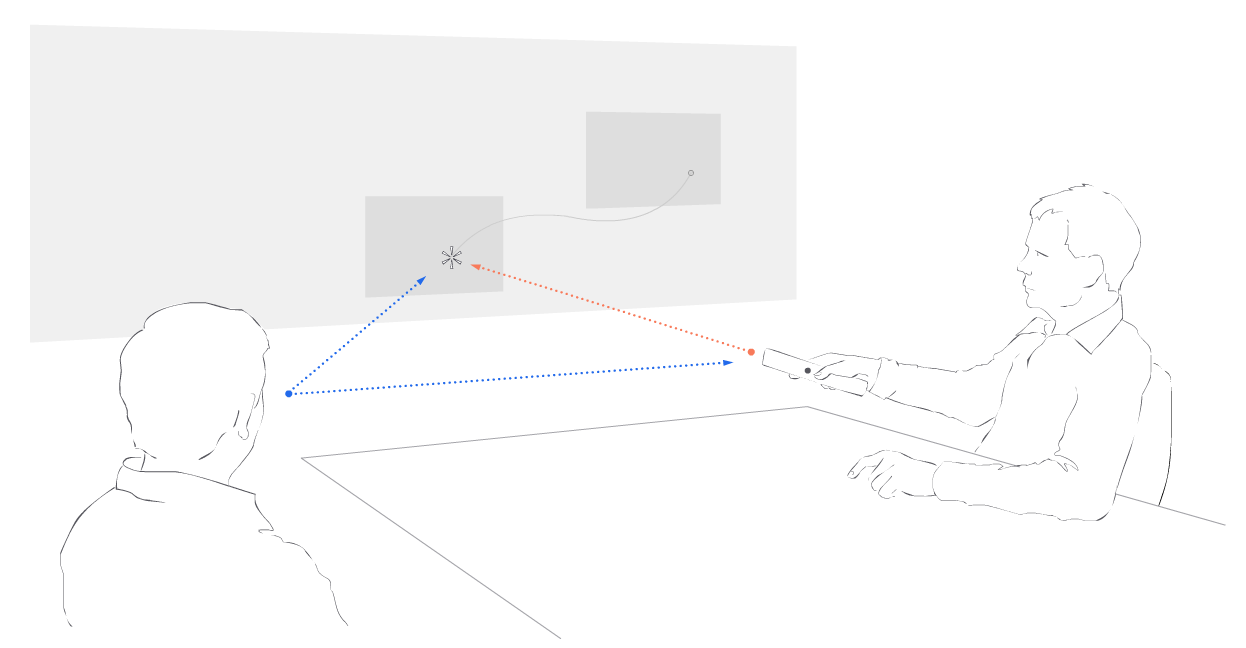
A spatial operating environment places valuable collaborative surfaces like whiteboards and tabletops on equal footing with their capable digital counterparts. In doing so, it pulls participants out of their personal screens back into a shared work space, encourages the flow of media and ideas across surfaces, and allows each participant to contribute and control the environment freely—all critical for collaborative work.
Into a Capable Future
A future built only of mobile computing isn't enough. Through their portability such devices are incredibly valuable, but this is offset by UIs that are reductive and incomplete. As devices and people become more mobile, we need an operating system that understands physical space—a fully capable, general purpose computing environment. This is what we've built: a system where all the critical characteristics of that UI (spatial, architectural-scale, collaborative, living) are built into
Interested in Learning More?
Start a conversation with our team to deliver the best collaboration experience for your teaming spaces.
Contact Us